Let’s get a primer on Databases from an Architectural perspective. Let’s understand the different terminology - Availability vs Durability vs RTO vs RPO vs Consistency.
You will learn
- What are the architectural parameters that you would need to consider when you design your databases?
- What is Availability of a Database?
- What is Durability of a Database?
- What is Consistency of a Database?
- What is RTO?
- What is RPO?
- What is Database design important when we talk about RTO and RPO?
- What is Availability of a Database?
Table of Contents
- Databases Primer
- Step I - Getting Started
- Step II - Snapshots
- Step III - Transaction Logs
- Step IV - Add a Standby
- Availability and Durability
- Durability
- Increasing Availability and Durability of Databases
- Database Terminology : RTO and RPO
- Achieving RTO and RPO - Failover Solutions
- STEP V : (New Scenario) Reporting and Analytics Applications
- Read Replicas
- Consistency
Databases Primer
Databases provide organized and persistent storage for your data.
To choose between different database types, we would need to understand:
- Availability
- Durability
- RTO
- RPO
- Consistency
- Transactions etc
Let’s get started on a simple journey to understand these.
Step I - Getting Started
Imagine a database deployed in a data center in London.
Let’s consider some challenges:
- Challenge 1: Your database will go down if the data center crashes or the server storage fails
- Challenge 2: You will lose data if the database crashes
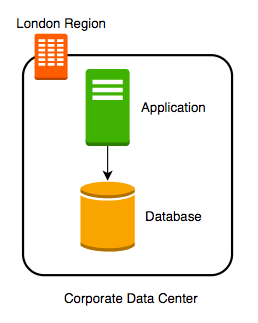
Step II - Snapshots
Let’s automate taking copy of the database (take a snapshot) every hour to another data center in London.
Let’s consider some challenges:
- Challenge 1: Your database will go down if the data center crashes
- Challenge 2 (PARTIALLY SOLVED): You will lose data if the database crashes
- You can setup database from latest snapshot. But depending on when failure occurs you can lose up to an hour of data
- Challenge 3(NEW): Database will be slow when you take snapshots
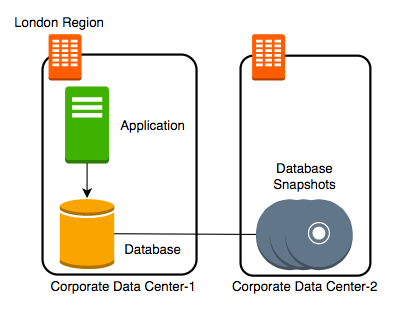
Step III - Transaction Logs
Let’s add transaction logs to database and create a process to copy it over to the second data center.
Let’s consider some challenges:
- Challenge 1: Your database will go down if the data center crashes
- Challenge 2 (SOLVED): You will lose data if the database crashes
- You can setup database from latest snapshot and apply transaction logs
- Challenge 3: Database will be slow when you take snapshots
![]()
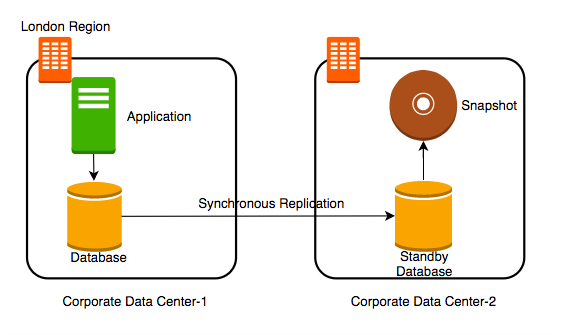
Step IV - Add a Standby
Let’s add a standby database in the second data center with replication.
Let’s consider some challenges:
- Challenge 1 (SOLVED): Your database will go down if the data center crashes
- You can switch to the standby database
- Challenge 2 (SOLVED): You will lose data if the database crashes
- Challenge 3 (SOLVED): Database will be slow when you take snapshots
- Take snapshots from standby.
- Applications connecting to master will get good performance always
Availability and Durability
What is Availability and What is Durability?
Availability
- Will I be able to access my data now and when I need it?
- Percentage of time an application provides the operations expected of it
Durability
- Will my data be available after 10 or 100 or 1000 years?
Examples of measuring availability and durability:
- 4 9’s - 99.99
- 11 9’s - 99.999999999
Typically, an availability of four 9’s is considered very good.
Typically, a durability of eleven 9’s is considered very good.
Here is a table showing examples of availability and the allowed downtime:
| Availability | Downtime (in a month) | Comment |
|---|---|---|
| 99.95% | 22 minutes | |
| 99.99% (4 9’s) | 4 and 1/2 minutes | Typically online apps aim for 99.99% (4 9’s) availability |
| 99.999% (5 9’s) | 26 seconds | Achieving 5 9’s availability is tough |
Durability
Will my data be available after 10 or 100 or 1000 years?
What does a durability of 11 9’s mean?
- If you store one million files for ten million years, you would expect to lose one file
Why should durability be high?
- Because we hate losing data
- Once we lose data, it is gone
Increasing Availability and Durability of Databases
How can we increase Availability and Durability of Databases?
Increasing Availability:
- Have multiple standbys available
- in multiple AZs
- in multiple Regions
Increasing Durability:
- Multiple copies of data (standbys, snapshots, transaction logs and replicas)
- in multiple AZs
- in multiple Regions
Replicating data comes with its own challenges!
- We will talk about them a little later
Database Terminology : RTO and RPO
Availability and Durability are technical measures.
How do we measure how quickly we can recover from failure?
- RPO (Recovery Point Objective): Maximum acceptable period of data loss
- RTO (Recovery Time Objective): Maximum acceptable downtime
Achieving minimum RTO and RPO is expensive. You need to Trade-off based on the criticality of the data.
Let’s look at an question:
You are running an EC2 instance storing its data on a EBS. You are taking EBS snapshots every 48 hours. If the EC2 instance crashes, you can manually bring it back up in 45 minutes from the EBS snapshot. What is your RTO and RPO?
- RTO - 45 minutes
- RPO - 48 hours
Achieving RTO and RPO - Failover Solutions
How can we achieve RTP and RPO?
Let’s look at a few scenarios:
| Scenario | Solution |
|---|---|
| Very small data loss (RPO - 1 minute) Very small downtime (RTO - 5 minutes) |
Hot standby - Automatically synchronize data Have a standby ready to pick up load Use automatic failover from master to standby |
| Very small data loss (RPO - 1 minute) BUT I can tolerate some downtimes (RTO - 15 minutes) |
Warm standby - Automatically synchronize data Have a standby with minimum infrastructure Scale it up when a failure happens |
| Data is critical (RPO - 1 minute) but I can tolerate downtime of a few hours (RTO - few hours) | Create regular data snapshots and transaction logs Create database from snapshots and transactions logs when a failure happens |
| Data can be lost without a problem (for example: cached data) | Failover to a completely new server |
STEP V : (New Scenario) Reporting and Analytics Applications
Let’s assume that new reporting and analytics applications are being launched using the same database which will ONLY read data.
Within a few days you see that the database performance is impacted.
How can we fix the problem?
Here are some of the options to consider:
- Vertically scale the database - increase CPU and memory
- Create a database cluster - typically database clusters are expensive to setup
- Create read replicas - Run read only applications against read replicas
Read Replicas
You can create a Read Replica and Connect reporting and analytics applications to read replica.
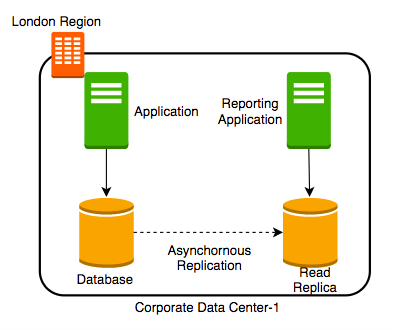
Here are the advantages and features:
- Reduces load on the master databases
- Upgrade read replica to master database (supported by some databases)
- Create read replicas in multiple regions
- Take snapshots from read replicas
Consistency
How do you ensure that data in multiple database instances (standbys and replicas) is updated simultaneously?
Here are the different types of consistency levels:
- Strong consistency - Synchronous replication to all replicas
- Will be slow if you have multiple replicas or standbys
- Eventual consistency - Asynchronous replication. A little lag - few seconds - before the change is available in all replicas
- In the intermediate period, different replicas might return different values
- Used when scalability is more important than data integrity
- Examples : Social Media Posts - Facebook status messages, Twitter tweets, Linked in posts etc
- Read-after-Write consistency - Inserts are immediately available. Updates and deletes are eventually consistent
- Amazon S3 provides read-after-write consistency