Let’s get a quick overview of AWS Data Lakes from an AWS certification perspective.
You will learn
- What is AWS Data Lakes?
- What are preferred Storage and Ingestion options in AWS Data Lakes?
- What is Amazon S3 Query in Place?
- Why is Data Cataloging important?
- How does AWS Glue help?
Table of Contents
- AWS Data Lakes - Simplified Big Data Solutions
- AWS Data Lakes - Storage and Ingestion
- Amazon S3 Query in Place
- AWS Data Lakes - Analytics with data in S3 Data Lake
- Data Cataloging
- AWS Glue
AWS Data Lakes - Simplified Big Data Solutions
Usually big data solutions are complex.
Here are some of the challenges with typical big data solutions:
- How can we make collecting, analyzing (reporting, analytics, machine learning) and visualizing huge data sets easy?
- How to design solutions that scale?
- How to build flexibility while saving cost?
Data Lakes provides a Single platform with combination of solutions for data storage, data management and data analytics.
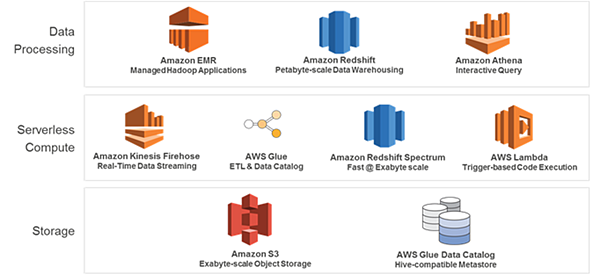
AWS Data Lakes - Storage and Ingestion
AWS Data Lakes makes use of varieties of AWS services for Storage and Ingestion:
- Storage
- Amazon S3 and S3 Glacier provide an ideal storage solution for data lakes
- Data Ingestion
- Streaming data - Amazon Kinesis Firehose
- Transform and store to Amazon S3
- Transformation operations - compress, encrypt, concatenate multiple records into one (to reduce S3 transactions cost) and execute lambda functions
- Bulk data from on-premises - AWS Snowball
- Integrate on-premises platforms with Amazon S3 - AWS Storage Gateway
- Streaming data - Amazon Kinesis Firehose
Amazon S3 Query in Place
Amazon S3 Query in Place allows you to run your analytics directly from Amazon S3 and S3 Glacier.
Here are some of the important options provided by S3 Select and Glacier Select:
- SQL queries to retrieve subset of data
- Supports CSV, JSON, Apache Parquet formats
- Build serverless apps connecting S3 Select with AWS Lambda
- Integrate into big data workflows
- Enable Presto, Apache Hive and Apache Spark frameworks to scan and filter data
Here are some of the important recommendations for S3 Query in Place:
- You want to get quick insights from your cold data stored in S3 Glacier. You want to run queries against archives stored in S3 Glacier without restoring the archives.
- Use S3 Glacier Select to perform filtering and basic querying using SQL queries
- Stores results in S3 bucket
- No need to temporarily stage data and then run queries
- Recommendations:
- Store data in Amazon S3 in Parquet format
- Reduce storage (upto 85%) and improve querying (upto 99%) compared to formats like CSV, JSON, or TXT
- Multiple compression standards are supported BUT GZIP is recommended
- Supported by Amazon Athena, Amazon EMR and Amazon Redshift
- Store data in Amazon S3 in Parquet format
Other options to run Query in Place include:
- Amazon Athena
- Direct ad-hoc SQL querying on data stored in S3
- Uses Presto and supports CSV, JSON, Apache Parquet and Avro
- Amazon Redshift Spectrum
- Run queries directly against S3 without loading complete data from S3 into a data warehouse
- Recommended if you are executing queries frequently against structured data
AWS Data Lakes - Analytics with data in S3 Data Lake
Here are some of the options to perform analytics with data in S3 Data Lake:
| Service | Description |
|---|---|
| Amazon EMR | EMR integrates well with Amazon S3 - Use big data frameworks like Apache Spark, Hadoop, Presto, or Hbase. For example: machine learning, graph analytics etc |
| Amazon Machine Learning (ML) | Create and run models for predictive analytics and machine learning (using data from Amazon S3, Amazon Redshift, or Amazon RDS) |
| Amazon QuickSight | For visualizations (using data from Amazon Redshift, Amazon RDS, Amazon Athena, and Amazon S3) |
| Amazon Rekognition | Build image recognition capabilities around images stored in Amazon S3. Example use case : Face based verification |
Data Cataloging
Data Cataloging is all about:
- 1 : What data (or assets) is stored?
- 2 : What is the format of data?
- 3 : How is the data structured?
Answers:
- Question 1 - Stored in comprehensive data catalog
- Questions 2 and 3 - Stored using a Hive Meta store Catalog (HCatalog)
AWS Glue also supports storing HCatalog.
AWS Glue
AWS Glue is a Fully managed extract, transform, and load (ETL) service in AWS.
Here are some of the important characteristics to remember:
- Simplify data preparation (capturing metadata) for analytics:
- Connect AWS Glue to your data on AWS (Aurora, RDS, Redshift, S3 etc)
- AWS Glue creates a AWS Glue Data Catalog with metadata abstracted from your data
- Your data is ready for searching and querying
- Run your ETL jobs using Apache Spark
- Metadata from AWS Glue Data Catalog can be used from:
- Amazon Athena
- Amazon EMR
- Amazon Redshift Spectrum